记录帮表姐写了一个txt转xlsx,同时进行格式转换和合并去重的脚本,最后将其打包成exe过程中遇到的小问题
格式转化
本身将有格式的txt转变为xlsx是没有难度的,只需要使用pd.read_csv(txt_path, sep='\t', header=0)即可轻松读入。
后续主要需要进行格式的变化,数据本身是一个对照试验,简单来说主要是两步:
- 根据已有列进行一个新列的计算,和一些格式上的修改
- 将现在延纵轴方向的concat转变为延横轴方向的concat,把一个6*41行的数据变成41行*6列(看图就懂了)
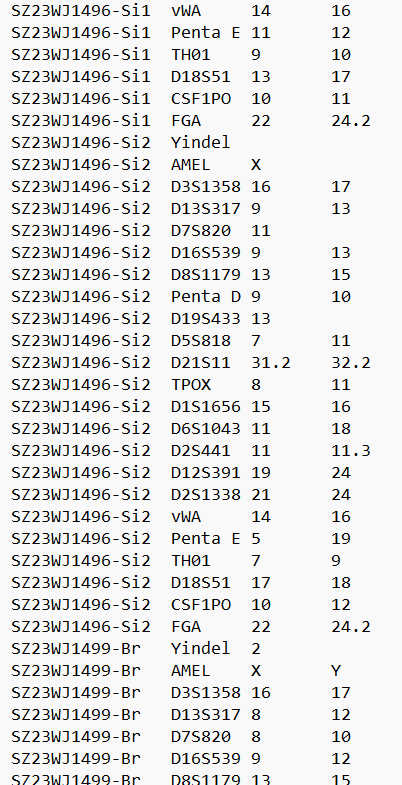
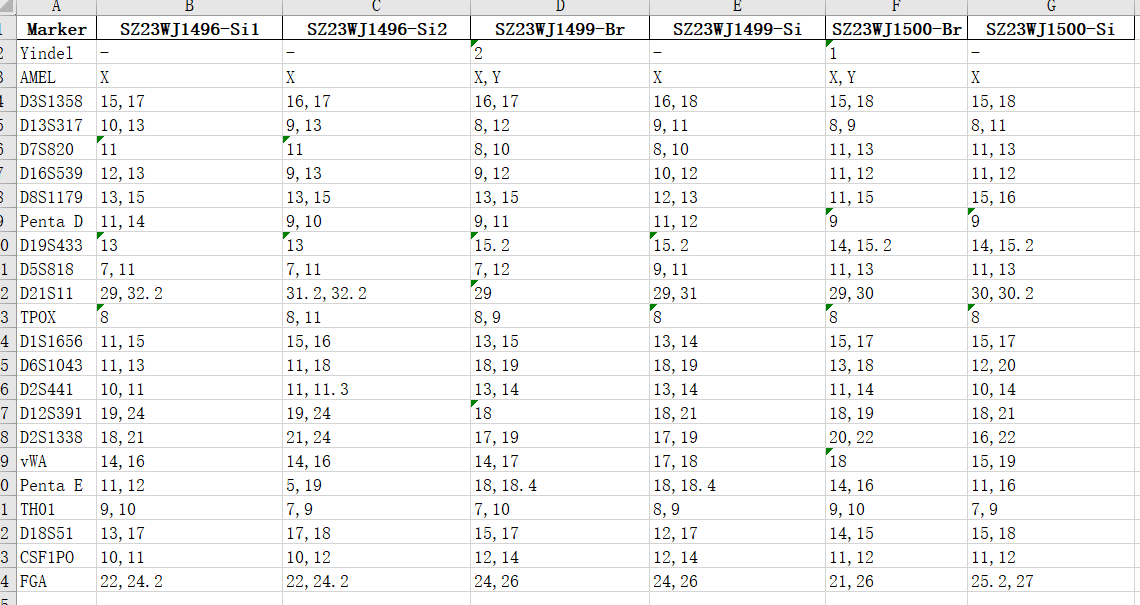
第二点主要思路就是先在第一列上建立索引,然后通过遍历索引一次取41行数据,不断地添加到一个空的dataframe上去。直接看代码吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import datetime
import glob
import os
import sys
import pandas as pd
import numpy as np
def get_res(df):
if df['Allele 1'] is not np.nan and df['Allele 2'] is not np.nan:
return ','.join([str(df['Allele 1']), str(df['Allele 2'])])
elif df['Allele 1'] is not np.nan:
return str(df['Allele 1'])
elif df['Allele 2'] is not np.nan:
return str(df['Allele 2'])
else:
return '-'
def format_txt(txt_path):
df = pd.read_csv(txt_path, sep='\t', header=0)
df = df.drop('Unnamed: 4', axis=1)
df['res'] = df.apply(get_res, axis=1)
df = df.drop(['Allele 1', 'Allele 2'], axis=1)
df = df.set_index('Sample Name')
row_index = list(set(df.index.tolist()))
row_index.sort()
res_df = pd.DataFrame()
res_df['Marker'] = df.reset_index()['Marker']
for i in row_index:
res_df[i] = df.loc[i, 'res'].reset_index()['res']
res_df = res_df.dropna()
return res_df
|
打包成exe
因为表姐那边不方便弄Python环境,他们也不太会用,所以我尝试直接将这个简单的脚本打包成exe。过程中遇到的最大的问题就是获取exe所在路径。
有很多获取路径的方法会获取到C盘中地某个临时文件,这可能和Python打包有关系,也可能和exe本身机制有关系。
我们需要使用os.path.dirname(os.path.realpath(sys.argv[0]))这行代码,这行代码是可以成功获取到exe文件所在目录了,其他什么os.path.dirname(os.path.abspath(__file__))这种亲测都是不行的。
最后附上完整代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| import datetime
import glob
import os
import sys
import pandas as pd
import numpy as np
def get_res(df):
if df['Allele 1'] is not np.nan and df['Allele 2'] is not np.nan:
return ','.join([str(df['Allele 1']), str(df['Allele 2'])])
elif df['Allele 1'] is not np.nan:
return str(df['Allele 1'])
elif df['Allele 2'] is not np.nan:
return str(df['Allele 2'])
else:
return '-'
def format_txt(txt_path):
df = pd.read_csv(txt_path, sep='\t', header=0)
df = df.drop('Unnamed: 4', axis=1)
df['res'] = df.apply(get_res, axis=1)
df = df.drop(['Allele 1', 'Allele 2'], axis=1)
df = df.set_index('Sample Name')
row_index = list(set(df.index.tolist()))
row_index.sort()
res_df = pd.DataFrame()
res_df['Marker'] = df.reset_index()['Marker']
for i in row_index:
res_df[i] = df.loc[i, 'res'].reset_index()['res']
res_df = res_df.dropna()
return res_df
if __name__ == '__main__':
input_list = glob.glob(os.path.join(os.path.dirname(os.path.realpath(sys.argv[0])), 'input/*.txt'))
print('在跑啦')
assert len(input_list) == 2
print('输入数据:', input_list[0], input_list[1])
df1 = format_txt(input_list[0])
df2 = format_txt(input_list[1])
df1 = df1.append(df2, ignore_index=True)
df1 = df1.drop_duplicates()
save_path = os.path.join(os.path.dirname(os.path.realpath(sys.argv[0])), 'output')
os.makedirs(save_path, exist_ok=True)
df1.to_excel(os.path.join(save_path, '合并_%s.xlsx' % datetime.datetime.now().strftime('%Y_%m_%d_%H_%M_%S')),
sheet_name='Sheet1', index=False)
|
对了,打包工具使用的是Pyinstaller,这里也简单记录下Pyinstaller最简单的使用方式。
使用这个命令可以将单个py文件打包成exe,多个py我还没有试过,这个应该是需要在有Python包的虚拟环境中去运行的,我是切到相应的虚拟环境中执行的,最后生成一个dist里面有个exe,盲猜不进合适的环境会出问题。
