昨天大致了解了一下什么是深度学习,深度学习,人工智能,机器学习之间有什么关系,深度学习框架的总览。今天来找找各个框架之间的对比和目前比较常用的tensorflow和pytorch一些资料。我觉得框架属实是个好东西,让我可以不用写CUDA,反正Django的ORM是属实舒服,轻松摆脱巨长的MySql,但是会有一些自己特殊的地方,比如插入一个带外键的数据时要先获取其主键Model,还是要多了解多记录。
参考
https://www.zhihu.com/question/330766768/answer/1398232292
https://www.zhihu.com/question/66200879
总览
上来先发一张图
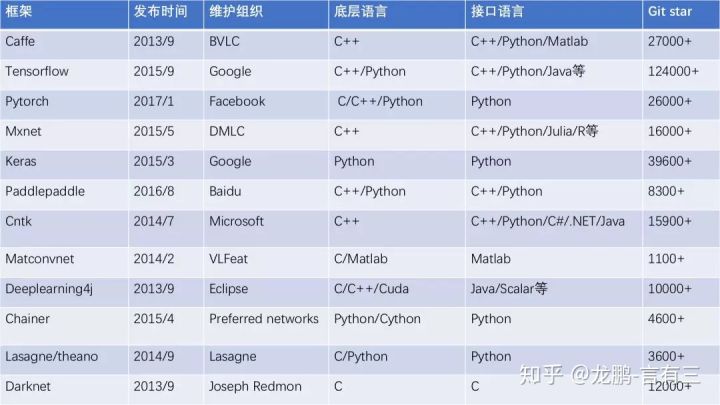
Caffe
**概述:**Caffe 是伯克利的贾扬清主导开发,以 C++/CUDA 代码为主,最早的深度学习框架之一,比TensorFlow、Mxnet、Pytorch 等都更早,需要进行编译安装。支持命令行、Python 和 Matlab 接口,单机多卡、多机多卡等都可以很方便的使用。目前 master 分支已经停止更新,intel 分支等还在维护,caffe 框架已经非常稳定。
通用流程:
准备数据——定义网络——配置训练参数——训练/测试
以上的流程相互之间是解耦合的,所以 caffe 的使用非常简单。
优点:
- 以 C++/CUDA/python 代码为主,速度快,性能高。
- 工厂设计模式,代码结构清晰,可读性和拓展性强。
- 支持命令行、Python 和 Matlab 接口,使用方便。
- CPU 和 GPU 之间切换方便,多 GPU 训练方便。
- 工具丰富,社区活跃。
缺点:
- 源代码修改门槛较高,需要实现前向反向传播,以及 CUDA 代码。
- 不支持自动求导。
- 不支持模型级并行,只支持数据级并行
- 不适合于非图像任务。
Tensorflow
**概述:**TensorFlow 是 Google brain 推出的开源机器学习库,可用作各类深度学习相关的任务。TensorFlow = Tensor + Flow,Tensor 就是张量,代表 N 维数组,这与 Caffe 中的 blob 是类似的;Flow 即流,代表基于数据流图的计算。
**特点:**TensorFlow 最大的特点是计算图,即先定义好图,然后进行运算,而且代码都包含两部分:
创建计算图,表示计算的数据流。可以将它看做是Caffe 中的 prototxt 的定义过程。
运行会话,执行图中的运算,可以看作是 Caffe 中的训练过程。会话比 Caffe 灵活很多,由于是 Python 接口,取中间结果分析,Debug 等方便很多。
Pytorch
概述: Pytorch = Python + Torch。Torch 是纽约大学的一个机器学习开源框架,但是由于使用的是一种绝大部分人绝对没有听过的 Lua 语言,导致很多人都被吓退。后来随着 Python 的生态越来越完善,Facebook 人工智能研究院推出了 Pytorch 并开源。Pytorch 不是简单的封装 Torch 并提供Python 接口,而是对 Tensor 以上的所有代码进行了重构,同 TensorFlow 一样,增加了自动求导。后来 Caffe2 全部并入 Pytorch,如今已经成为了非常流行的框架。
特点:
- 动态图计算。TensorFlow 从静态图发展到了动态图机制 Eager Execution ,pytorch 则一开始就是动态图机制。动态图机制的好处就是随时随地修改,随处 debug ,没有类似编译的过程。
- 简单。相比 TensorFlow1.0 中 Tensor、Variable、Session 等概念充斥,数据读取接口频繁更新,tf.nn、tf.layers、tf.contrib 各自重复,Pytorch 则是从 Tensor 到 Variable 再到nn.Module ,最新的Pytorch 已经将 Tensor 和 Variable 合并,这分别就是从数据张量到网络的抽象层次的递进。
Mxnet
概述: Mxnet 是由李沐等人领导开发的非常灵活,扩展性很强的框架,被 Amazon 定为官方框架。
特点: Mxnet 同时拥有命令式编程和符号式编程的特点。在命令式编程上 MXNet 提供张量运算,进行模型的迭代训练和更新中的控制逻辑;在声明式编程中 MXNet 支持符号表达式,用来描述神经网络,并利用系统提供的自动求导来训练模型。Mxnet 性能非常高,推荐资源不够的同学使用。
Keras
概述: Keras 是一个对小白用户非常友好而简单的深度学习框架,严格来说并不是一个开源框架,而是一个高度模块化的神经网络库。Keras 在高层可以调用 TensorFlow,CNTK,Theano ,还有更多的库也在被陆续支持中。 Keras 的特点是能够快速实现模型的搭建,是高效地进行科学研究的关键。
特点:
- 高度模块化,搭建网络非常简洁。
- API 很简单,具有统一的风格。
- 容易扩展,只需使用 python 添加新类和函数。
Paddlepaddle
概述: 正所谓 Google 有 Tensorflow,Facebook 有 Pytorch,Amazon 有 Mxnet,作为国内机器学习的先驱,百度也有 PaddlePaddle,其中 Paddle 即 Parallel Distributed Deep Learning (并行分布式深度学习)。
**特点:**paddle 的性能也很不错,整体使用起来与 tensorflow 非常类似,拥有中文帮助文档,在百度内部也被用于推荐等任务。另外,配套了一个可视化框架 visualdl,与 tensorboard 也有异曲同工之妙。
CNTK
**概述:**CNTK 是微软开源的深度学习工具包,它通过有向图将神经网络描述为一系列计算步骤。在有向图中,叶节点表示输入值或网络参数,而其他节点表示其输入上的矩阵运算。CNTK 允许用户非常轻松地实现和组合流行的模型,包括前馈 DNN,卷积网络(CNN)和循环网络(RNN / LSTM)。与目前大部分框架一样,实现了自动求导,利用随机梯度下降方法进行优化。
特点:
- CNTK 性能较高,按照其官方的说法,比其他的开源框架性能都更高。
- 适合做语音,CNTK 本就是微软语音团队开源的,自然是更合适做语音任务,使用 RNN 等模型,以及在时空尺度分别进行卷积非常容易。
Matconvnet
**概述:**不同于各类深度学习框架广泛使用的语言 Python,MatConvnet 是用 matlab 作为接口语言的开源深度学习库,底层语言是 cuda。
**特点:**因为是在 matlab 下面,所以 debug 的过程非常的方便,而且本身就有很多的研究者一直都使用 matlab 语言。
Deeplearning4j
**概述:**不同于深度学习广泛应用的语言 Python,DL4J 是为 java 和 jvm 编写的开源深度学习库,支持各种深度学习模型。
**特点:**DL4J 最重要的特点是支持分布式,可以在 Spark 和 Hadoop 上运行,支持分布式 CPU 和 GPU 运行。DL4J 是为商业环境,而非研究所设计的,因此更加贴近某些生产环境。
Chainer
**概述:**chainer 也是一个基于 python 的深度学习框架,能够轻松直观地编写复杂的神经网络架构,在日本企业中应用广泛。
特点: chainer 采用 “Define-by-Run” 方案,即通过实际的前向计算动态定义网络。更确切地说,chainer 存储计算历史而不是编程逻辑,pytorch 的动态图机制思想主要就来源于 chaine。
Lasagne/Theano
概述: Lasagen 其实就是封装了的 theano,后者是一个很老牌的框架,在 2008 年的时候就由 Yoshua Bengio 领导的蒙特利尔 LISA 组开源了。
特点: theano 的使用成本高,需要从底层开始写代码构建模型,Lasagen 对其进行了封装,使得 theano 使用起来更简单。
Darknet
概述: Darknet 本身是 Joseph Redmon 为了 Yolo 系列开发的框架。
特点: Darknet 几乎没有依赖库,是从 C 和 CUDA 开始撰写的深度学习开源框架,支持 CPU 和 GPU。Darknet跟 caffe 颇有几分相似之处,却更加轻量级,非常值得学习使用。
模型的求导
在上面的学习中经常可以看到很多框架具有自动求导(Automatic Differentiation,AD)的功能,那么什么是自动求导功能呢,于是我又找了找资料记录如下:
最近在上关于 自动求导 (Automatic Differentiation, AD) 的课程 (CS207),正好来回答一下。 其实不只是 TensorFlow,Pytorch 这些为深度学习设计的库用到 AD,很多物理,化学等基础科学计算软件也在大量的使用 AD。而且,其实TensorFlow、Pytorch 也并非只能用于deep learning,本质上他们是一种
Tensor computation built on a tape-based autograd system --引自Pytorch
张量计算建立在一个基于卷积的自动梯度系统之上(渣渣的自翻)
自动求导分成两种模式,一种是 Forward Mode,另外一种是 Reverse Mode。一般的机器学习库用的后一种,原因后面说。
Forward Mode
基于的就是就最基本的 链式法则 chain rule,

这个 Forward Mode 就是用 chain rule,像剥洋葱一样一层一层算出来,以

为例。我们可以把他的计算图画出来。
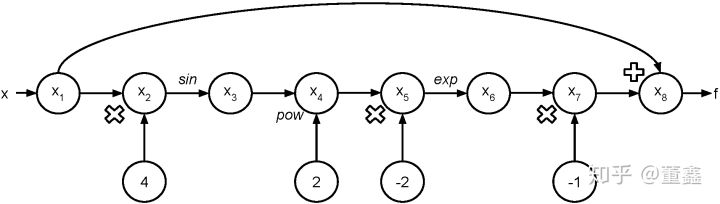
假如我要计算$f’(\frac{\pi}{16})$,可以根据上面的图得到一个表格
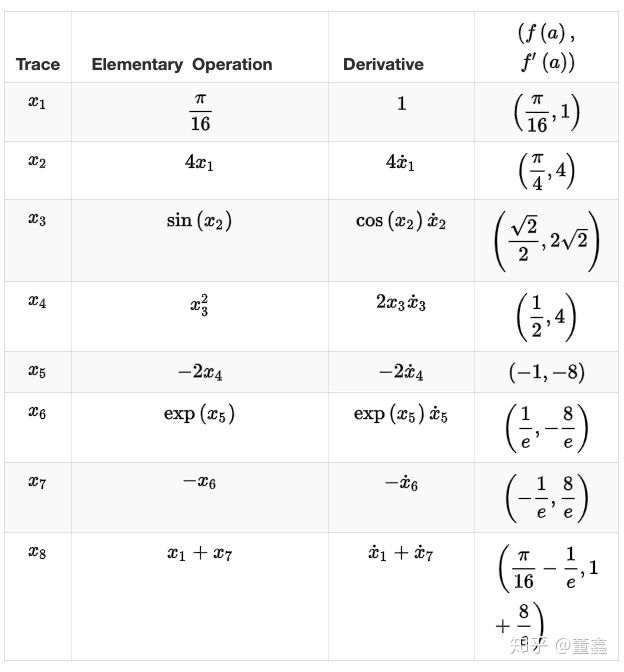
那么上面这个表里,每一步我们既要算 forward 的值 $f(a)$ ,也要算 backward 的值$f’(a)$。
有没有办法同时把这两个值算出来呢?
首先引入一个新的概念,二元数。二元数其实跟复数差不多,也是一种实数的推广。我们回忆一下,一个复数可以写成这样的形式:
二元数其实跟复数差不多,也是一种实数的推广。我们回忆一下,一个复数可以写成这样的形式:
$z = a + ib$ ; $i^2 = -1$
对于复数的理解,一个比较直观的例子就是。本来实数都是在一个实数轴(x轴)的。复部 $ib$ 相当于多了一个 y 轴出来。
那么二元数是这个亚子:
$z = a + \epsilon b$ ; $\epsilon^2 = 0$
这个二元数很神奇的一个性质是,你带着他做运算,得出来的二元部 $\epsilon b$ 前面的系数,就是导数。举个栗子, 我们要求

我们可以令 $x = a + \epsilon b$,所以

我们把上面的三角函数展开,

得到

可以看到,二元部 $\cos(a)$ 恰好就是原函数 $\sin(a)$ 的导数。
Reverse Mode
这个模式就比较简单和直接了。就是说,上面那个表里面,我每次只计算每个“小运算”的梯度(也是是那个图里面的每个节点),最后我再根据 chain rule 把“小运算”们的梯度串起来。其实 forward mode 和 reverse mode 并没有本质的区别,只是说,reverse mode在计算梯度先不考虑 chain rule,最后再用 chain rule 把梯度组起来。而前者则是直接就应用 chain rule 来算梯度。
下面总结一下 reverse mode 的流程:
- 创建计算图
- 计算前向传播的值及每个操作的梯度
- 这里没有
chain rule的事 - 比如这个操作是乘法 $x_3 = x_1*x_2$,那么我们只需要把 $\frac{\partial x_3}{\partial x_2}$ 以及 $\frac{\partial x_3}{\partial x_1}$ 算出来就好了
- 这里没有
- 反向计算梯度从最后一个节点(操作)开始:$\overline{x_N} = \frac{\partial f}{\partial x_N} = 1$ , $f = x_N$
- 根据
chain rule逐层推进 $\overline{x_{N-1}} = \frac{\partial f}{\partial x_N}\frac{\partial x_N}{\partial x_{N-1}}$ - 假如有多条求导路径,我们要把他们加起来,例如 $\overline{x_3} = \frac{\partial f}{\partial x_3} = \frac{\partial f}{\partial x_4}\frac{\partial x_4}{\partial x_3} + \frac{\partial f}{\partial x_5}\frac{\partial x_5}{\partial x_3}$
举个栗子,我们要计算函数
在点 $a = (1,2)$ 的导数
首先还是先把计算图画出来
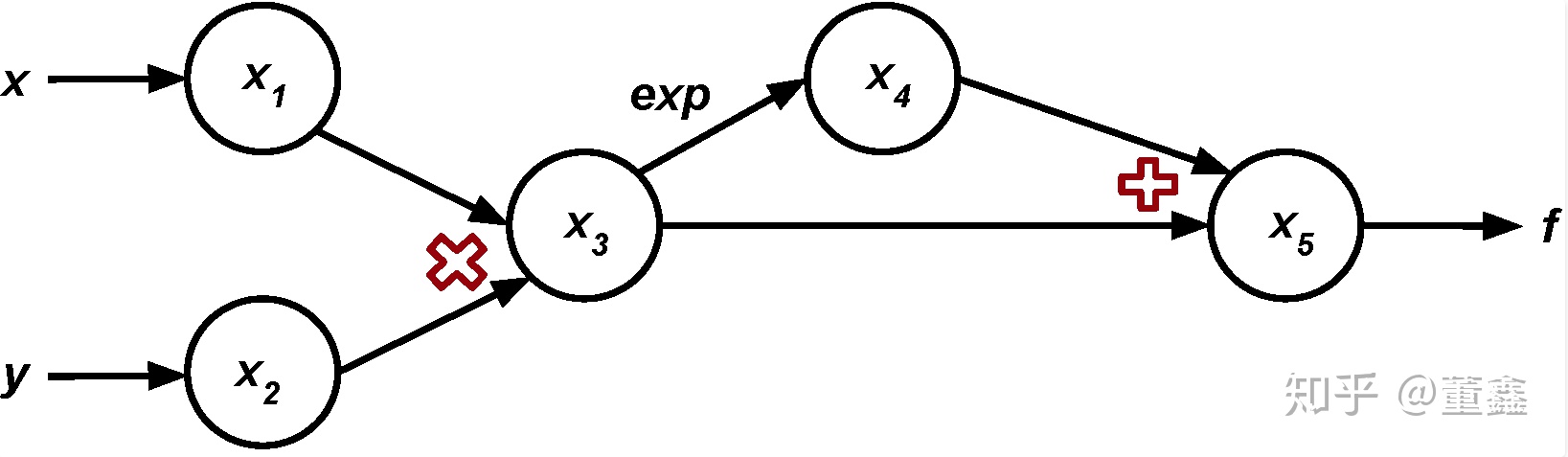
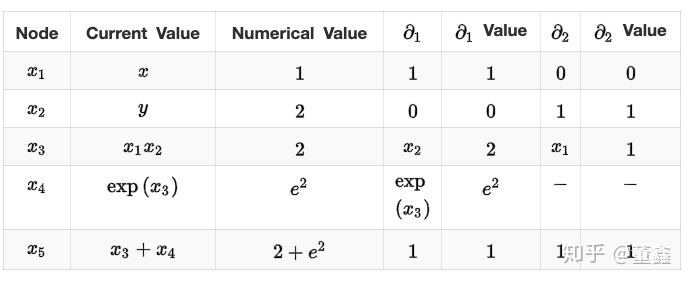
我们逐层的抽丝剥茧,

总结
- 可以很清楚的看到,在训练人工神经网络时常用的
backpropagation也是属于reverse mode的。 - 假如我们要计算的梯度的函数是 $f : R^m \rightarrow R^n$
- 如果 n 是相对比较大的话,用
forward比较省计算 - 如果 m 是相对比较大的话,用
reverse比较省计算
TensorFlow与PyTorch之争
我们可以用 TensorFlow 和 PyTorch 构建什么?
神经网络起初是被用于解决手写数字识别或用相机识别汽车注册车牌等简单的分类问题。但随着近来框架的发展以及英伟达高计算性能图形处理单元(GPU)的进步,我们可以在 TB 级的数据上训练神经网络并求解远远更加复杂的问题。一个值得提及的成就是在 TensorFlow 和 PyTorch 中实现的卷积神经网络在 ImageNet 上都达到了当前最佳的表现。训练后的模型可以用在不同的应用中,比如目标检测、图像语义分割等等。
尽管神经网络架构可以基于任何框架实现,但结果却并不一样。训练过程有大量参数都与框架息息相关。举个例子,如果你在 PyTorch 上训练一个数据集,那么你可以使用 GPU 来增强其训练过程,因为它们运行在 CUDA(一种 C++ 后端)上。TensorFlow 也能使用 GPU,但它使用的是自己内置的 GPU 加速。因此,根据你所选框架的不同,训练模型的时间也总是各不相同。
PyTorch 和 TensorFlow 对比
PyTorch 和 TensorFlow 的关键差异是它们执行代码的方式。这两个框架都基于基础数据类型张量(tensor)而工作。你可以将张量看作是下图所示的多维数组。
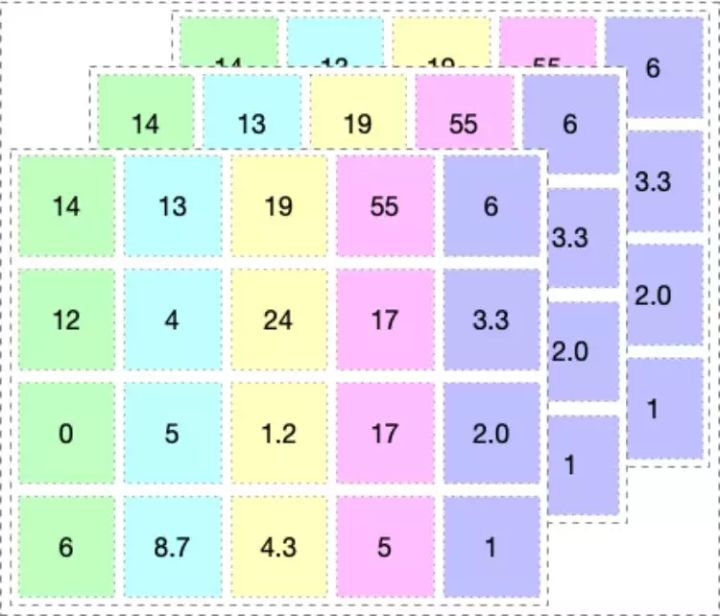
机制:动态图定义与静态图定义
TensorFlow 框架由两个核心构建模块组成:
- 一个用于定义计算图以及在各种不同硬件上执行这些图的运行时间的软件库。
- 一个具有许多优点的计算图(后面很快就会介绍这些优点)。
计算图是一种将计算描述成有向图的抽象方式。图是一种由节点(顶点)和边构成的数据结构,是由有向的边成对连接的顶点的集合。
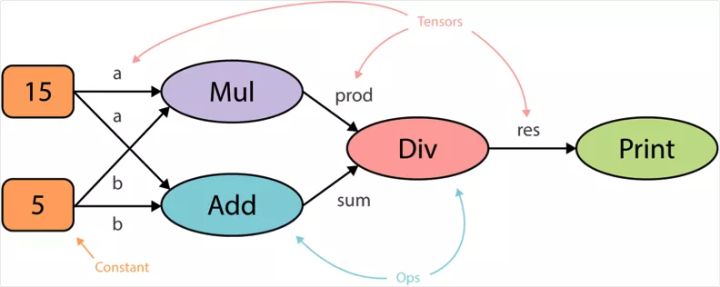
当你在 TensorFlow 中运行代码时,计算图是以静态方式定义的。与外部世界的所有通信都是通过 tf.Sessionobject 和 tf.Placeholder 执行,它们是在运行时会被外部数据替换的张量。例如,看看以下代码段:
1 | a = 15 |
下图是 TensorFlow 中运行代码之前以静态方式生成计算图的方式。计算图的核心优势是能实现并行化或依赖驱动式调度(dependency driving scheduling),这能让训练速度更快,更有效率。
类似于 TensorFlow,PyTorch 也有两个核心模块:
- 计算图的按需和动态构建
- Autograd:执行动态图的自动微分
可以在下图中看到,图会随着执行过程而改变和执行节点,没有特殊的会话接口或占位符。整体而言,这个框架与 Python 语言的整合更紧密,大多数时候感觉更本地化。因此,PyTorch 是更 Python 化的框架,而 TensorFlow 则感觉完全是一种新语言。

根据你所用的框架,在软件领域有很大的不同。TensorFlow 提供了使用 TensorFlow Fold 库实现动态图的方式,而 PyTorch 的动态图是内置的。分布式训练PyTorch 和 TensorFlow 的一个主要差异特点是数据并行化。PyTorch 优化性能的方式是利用 Python 对异步执行的本地支持。而用 TensorFlow 时,你必须手动编写代码,并微调要在特定设备上运行的每个操作,以实现分布式训练。但是,你可以将 PyTorch 中的所有功能都复现到 TensorFlow 中,但这需要做很多工作。下面的代码片段展示了用 PyTorch 为模型实现分布式训练的简单示例:

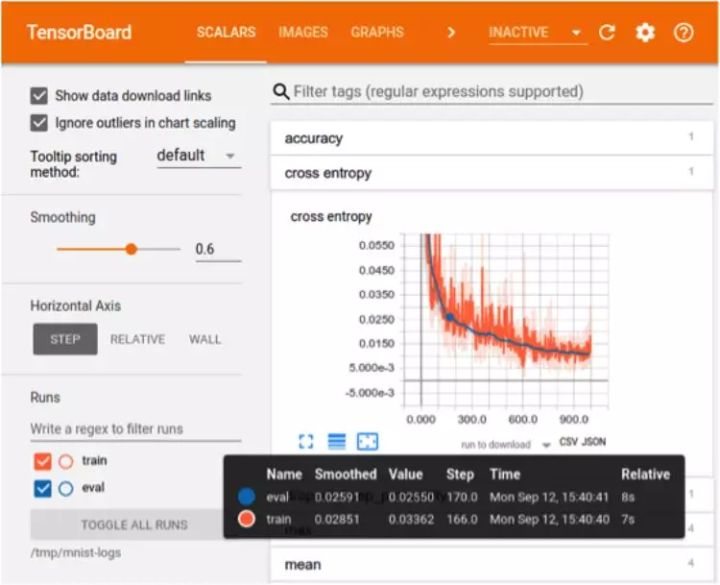
可视化
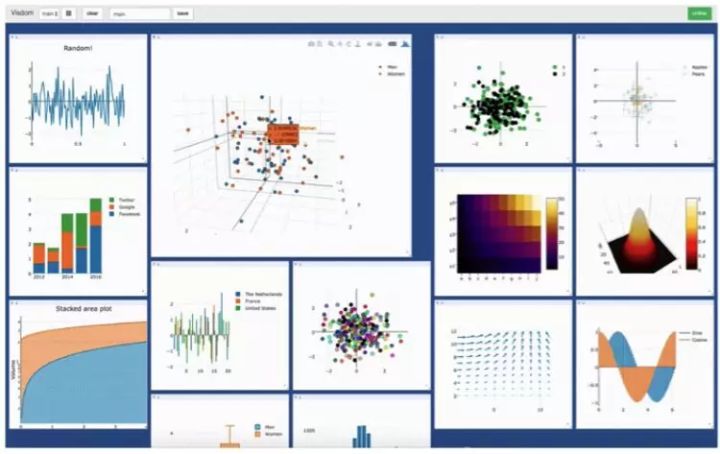
在训练过程的可视化方面,TensorFlow 更有优势。可视化能帮助开发者跟踪训练过程以及实现更方便的调试。TensorFlow 的可视化库名为 TensorBoard。PyTorch 开发者则使用 Visdom,但是 Visdom 提供的功能很简单且有限,所以 TensorBoard 在训练过程可视化方面更好。TensorBoard 的特性:
- 跟踪和可视化损失和准确度等指标
- 可视化计算图(操作和层)
- 查看权重、偏差或其它张量随时间变化的直方图
- 展示图像、文本和音频数据
- 分析 TensorFlow 程序
Visdom 的特性
- 处理回调
- 绘制图表和细节
- 管理环境
生产部署
在将训练好的模型部署到生产方面,TensorFlow 显然是赢家。我们可以直接使用 TensorFlow serving 在 TensorFlow 中部署模型,这是一种使用了 REST Client API 的框架。使用 PyTorch 时,在最新的 1.0 稳定版中,生产部署要容易一些,但它没有提供任何用于在网络上直接部署模型的框架。你必须使用 Flask 或 Django 作为后端服务器。所以,如果要考虑性能,TensorFlow serving 可能是更好的选择。
用 PyTorch 和 TensorFlow 定义一个简单的神经网络
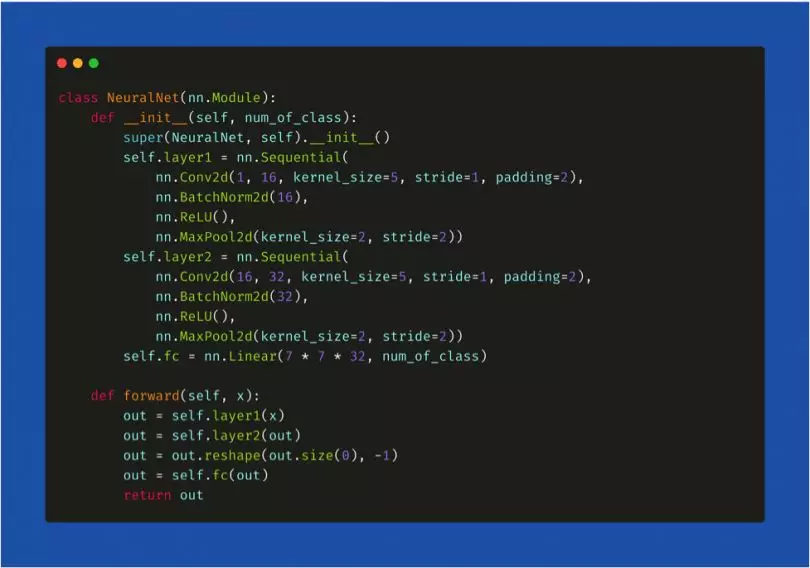
我们比较一下如何在 PyTorch 和 TensorFlow 中声明神经网络。在 PyTorch 中,神经网络是一个类,我们可以使用 torch.nn 软件包导入构建架构所必需的层。所有的层都首先在 init() 方法中声明,然后在 forward() 方法中定义输入 x 在网络所有层中的遍历方式。最后,我们声明一个变量模型并将其分配给定义的架构(model = NeuralNet())。
近期 Keras 被合并到了 TensorFlow 库中,这是一个使用 TensorFlow 作为后端的神经网络框架。从那时起,在 TensorFlow 中声明层的句法就与 Keras 的句法类似了。首先,我们声明变量并将其分配给我们将要声明的架构类型,这里的例子是一个 Sequential() 架构。接下来,我们使用 model.add() 方法以序列方式直接添加层。层的类型可以从 tf.layers 导入,如下代码片段所示:
TensorFlow 和 PyTorch 的优缺点
TensorFlow和PyTorch各有其优缺点。
TensorFlow 的优点:
- 简单的内置高级 API
- 使用 TensorBoard 可视化训练
- 通过 TensorFlow serving 容易实现生产部署
- 很容易的移动平台支持
- 开源
- 良好的文档和社区支持
TensorFlow 的缺点:
- 静态图
- 调试方法
- 难以快速修改
PyTorch 的优点
- 类 Python 的代码
- 动态图
- 轻松快速的编辑
- 良好的文档和社区支持
- 开源
- 很多项目都使用 PyTorch
PyTorch 的缺点:
- 可视化需要第三方
- 生产部署需要 API 服务器
