待录取已经下来了,应该没什么意外就尘埃落定了,这几天都没怎么睡好,下午困得很。今天下午和晚上就看看什么是深度学习,稍微了解一下,晚上跑个步回去早点睡。
参考
https://baike.baidu.com/item/深度学习/3729729?fr=aladdin
https://www.zhihu.com/question/24097648
https://blog.csdn.net/testcs_dn/article/details/85009917
什么是深度学习
人工智能、机器学习、深度学习这几个名词都很火热,但是他们到底是什么意思呢。
根据我的查找发现,机器学习是实现人工智能的一种方式,而深度学习又是实现机器学习的一种方式,所以他们应该是一种包含的关系。类似于下图

机器学习、神经网络、深度学习
机器学习
简单的说机器学习就是让机器去分析数据找规律,并通过找到的规律对新的数据进行处理。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。**机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。**因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。很多推论问题属于无程序可循难度,所以部分的机器学习研究是开发容易处理的近似算法。
神经网络
神经网络简单点将就是由好多个神经元组成的系统。这是模拟人类的神经网络。
神经元是一个简单的分类器。
比如我们有一大堆猫、狗照片,把每一张照片送进一个机器里,机器需要判断这幅照片里的东西是猫还是狗。我们把猫狗图片处理一下,左边是狗的特征向量,右边是猫的。

神经元一个缺点是:它只能切一刀!你给我说说一刀怎么能把下面这两类分开吧。
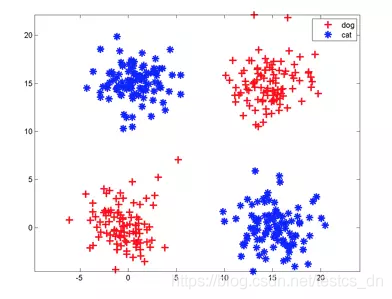
解决办法是多层神经网络,底层神经元的输出是高层神经元的输入。我们可以在中间横着砍一刀,竖着砍一刀,然后把左上和右下的部分合在一起,与右上的左下部分分开;也可以围着左上角的边沿砍10刀把这一部分先挖出来,然后和右下角合并。
每砍一刀,其实就是使用了一个神经元,把不同砍下的半平面做交、并等运算,就是把这些神经元的输出当作输入,后面再连接一个神经元。这个例子中特征的形状称为异或,这种情况一个神经元搞不定,但是两层神经元就能正确对其进行分类。
只要你能砍足够多刀,把结果拼在一起,什么奇怪形状的边界神经网络都能够表示,所以说神经网络在理论上可以表示很复杂的函数/空间分布。但是真实的神经网络是否能摆动到正确的位置还要看网络初始值设置、样本容量和分布。
深度学习
那什么是深度学习呢?深度学习简单点说就是一种为了让层数较多的多层神经网络可以训练,能够运行起来而演化出来的一系列的新的结构和新的方法。
**深度学习(Deep Learning)**是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习是无监督学习的一种。
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
就像下图
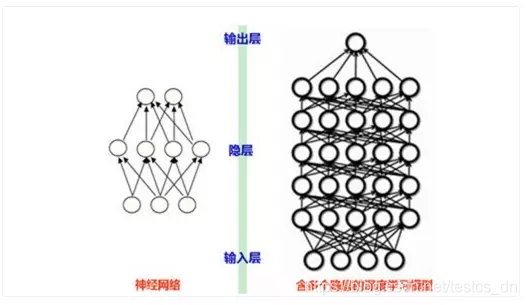
普通的神经网络可能只有几层,深度学习可以达到十几层。深度学习中的深度二字也代表了神经网络的层数。现在流行的深度学习网络结构有"CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的等。
机器学习是人工智能的一个子集,深度学习又是机器学习的一个子集。机器学习与深度学习都是需要大量数据支撑的,是大数据技术上的一个应用,同时深度学习还需要更高的运算能力支撑,如GPU。
深度学习典型模型
典型的深度学习模型有卷积神经网络( convolutional neural network)、DBN和堆栈自编码网络(stacked auto-encoder network)模型等,下面对这些模型进行描述。
卷积神经网络模型

在无监督预训练出现之前,训练深度神经网络通常非常困难,而其中一个特例是卷积神经网络。卷积神经网络受视觉系统的结构启发而产生。第一个卷积神经网络计算模型是在Fukushima(D的神经认知机中提出的,基于神经元之间的局部连接和分层组织图像转换,将有相同参数的神经元应用于前一层神经网络的不同位置,得到一种平移不变神经网络结构形式。后来,Le Cun等人在该思想的基础上,用误差梯度设计并训练卷积神经网络,在一些模式识别任务上得到优越的性能。至今,基于卷积神经网络的模式识别系统是最好的实现系统之一,尤其在手写体字符识别任务上表现出非凡的性能。
深度信任网络模型
DBN可以解释为贝叶斯概率生成模型,由多层随机隐变量组成,上面的两层具有无向对称连接,下面的层得到来自上一层的自顶向下的有向连接,最底层单元的状态为可见输入数据向量。DBN由若2F结构单元堆栈组成,结构单元通常为RBM(RestIlcted Boltzmann Machine,受限玻尔兹曼机)。堆栈中每个RBM单元的可视层神经元数量等于前一RBM单元的隐层神经元数量。根据深度学习机制,采用输入样例训练第一层RBM单元,并利用其输出训练第二层RBM模型,将RBM模型进行堆栈通过增加层来改善模型性能。在无监督预训练过程中,DBN编码输入到顶层RBM后,解码顶层的状态到最底层的单元,实现输入的重构。RBM作为DBN的结构单元,与每一层DBN共享参数。
堆栈自编码网络模型
堆栈自编码网络的结构与DBN类似,由若干结构单元堆栈组成,不同之处在于其结构单元为自编码模型( auto-en-coder)而不是RBM。自编码模型是一个两层的神经网络,第一层称为编码层,第二层称为解码层。
CUAD(Compute Unified Device Architecture)
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
在上文提到了,深度学习需要多的数据来进行学习,那么计算能力就是很重要的一环。
随着GPU的不断发展,它在计算能力上已经超过了通用CPU,仅仅用来做显卡有点浪费了。于是开发人员就将目光瞄向了GPU。
像许多的技术方向一样,深度学习也拥有着自己的框架,它可以让开发人员不需要手写CUDA就能跑GPU。
深度学习框架
为何要用深度学习框架?
- 不需要手写CUDA就能跑GPU
- 自动帮你复杂复合函数的梯度
深度学习从此变得傻瓜!
框架总览
现如今开源生态非常完善,深度学习相关的开源框架众多,光是为人熟知的就有caffe,tensorflow,pytorch/caffe2,keras,mxnet,paddldpaddle,theano,cntk,deeplearning4j,matconvnet等。
如何选择最适合你的开源框架是一个问题。有三AI在前段时间里,给大家整理了12个深度学习开源框架快速入门的教程和代码,供初学者进行挑选,一个合格的深度学习算法工程师怎么着得熟悉其中的3个以上吧。
下面是各大开源框架的一个总览。
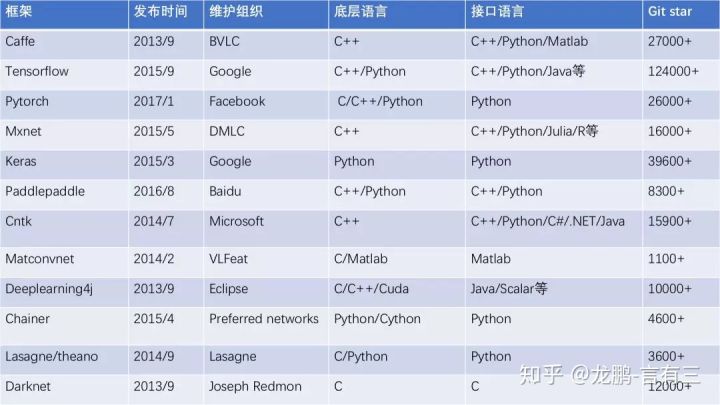
(1) 不管怎么说,tensorflow/pytorch你都必须会,这是目前开发者最喜欢,开源项目最丰富的两个框架。
(2) 如果你要进行移动端算法的开发,那么Caffe是不能不会的。
(3) 如果你非常熟悉Matlab,matconvnet你不应该错过。
(4) 如果你追求高效轻量,那么darknet和mxnet你不能不熟悉。
(5) 如果你很懒,想写最少的代码完成任务,那么用keras吧。
(6) 如果你是java程序员,那么掌握deeplearning4j没错的。
其他的框架,也自有它的特点,大家可以自己多去用用。
监督学习与非监督学习
监督学习(supervised learning)
从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类(注意和聚类区分)问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统(模型)。
监督学习是训练神经网络和决策树的常见技术。这两种技术高度依赖事先确定的分类系统给出的信息,对于神经网络,分类系统利用信息判断网络的错误,然后不断调整网络参数。对于决策树,分类系统用它来判断哪些属性提供了最多的信息。
常见的有监督学习算法:回归分析和统计分类。最典型的算法是KNN和SVM。
有监督学习最常见的就是:regression&classification
Regression:Y是实数vector。回归问题,就是拟合(x,y)的一条曲线,使得价值函数(costfunction) L最小
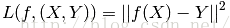
Classification:Y是一个有穷数(finitenumber),可以看做类标号,分类问题首先要给定有lable的数据训练分类器,故属于有监督学习过程。分类过程中cost function l(X,Y)是X属于类Y的概率的负对数。
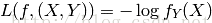
其中fi(X)=P(Y=i|X)。

无监督学习(unsupervised learning)
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
非监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情。非监督学习有两种思路。第一种思路是在指导Agent时不为其指定明确分类,而是在成功时,采用某种形式的激励制度。需要注意的是,这类训练通常会置于决策问题的框架里,因为它的目标不是为了产生一个分类系统,而是做出最大回报的决定,这种思路很好的概括了现实世界,agent可以对正确的行为做出激励,而对错误行为做出惩罚。
无监督学习的方法分为两大类:
(1) 一类为基于概率密度函数估计的直接方法:指设法找到各类别在特征空间的分布参数,再进行分类。
(2) 另一类是称为基于样本间相似性度量的简洁聚类方法:其原理是设法定出不同类别的核心或初始内核,然后依据样本与核心之间的相似性度量将样本聚集成不同的类别。
利用聚类结果,可以提取数据集中隐藏信息,对未来数据进行分类和预测。应用于数据挖掘,模式识别,图像处理等。
PCA和很多deep learning算法都属于无监督学习。
两者的不同点
-
有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
-
有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
-
非监督学习方法在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集的目的,也就是说不一定要“分类”。
这一点是比有监督学习方法的用途要广。 譬如分析一堆数据的主分量,或分析数据集有什么特点都可以归于非监督学习方法的范畴。
-
用非监督学习方法分析数据集的主分量与用K-L变换计算数据集的主分量又有区别。后者从方法上讲不是学习方法。因此用K-L变换找主分量不属于无监督学习方法,即方法上不是。而通过学习逐渐找到规律性这体现了学习方法这一点。在人工神经元网络中寻找主分量的方法属于无监督学习方法。
何时采用哪种方法
简单的方法就是从定义入手,有训练样本则考虑采用监督学习方法;无训练样本,则一定不能用监督学习方法。但是,现实问题中,即使没有训练样本,我们也能够凭借自己的双眼,从待分类的数据中,人工标注一些样本,并把它们作为训练样本,这样的话,可以把条件改善,用监督学习方法来做。对于不同的场景,正负样本的分布如果会存在偏移(可能大的偏移,可能比较小),这样的话,监督学习的效果可能就不如用非监督学习了。
